
IBM Merges Data Lakehouse and Parallel File System for Advanced AI
IBM has integrated its watsonx.data and Storage Scale products to create a scalable platform for AI processing and analytics.
This innovative solution combines data lakehouse capabilities with parallel file system features to deliver exceptional performance for AI workloads.
The platform boasts enhanced AI performance through GPU Direct Storage (GDS) in partnership with Nvidia, accelerating the training of generative AI models.
It supports multi-protocol operations for streamlined workflows and offers a unified data platform for both analytics and AI. Additionally, it enables retrieval-augmented generation (RAG) using proprietary customer data.
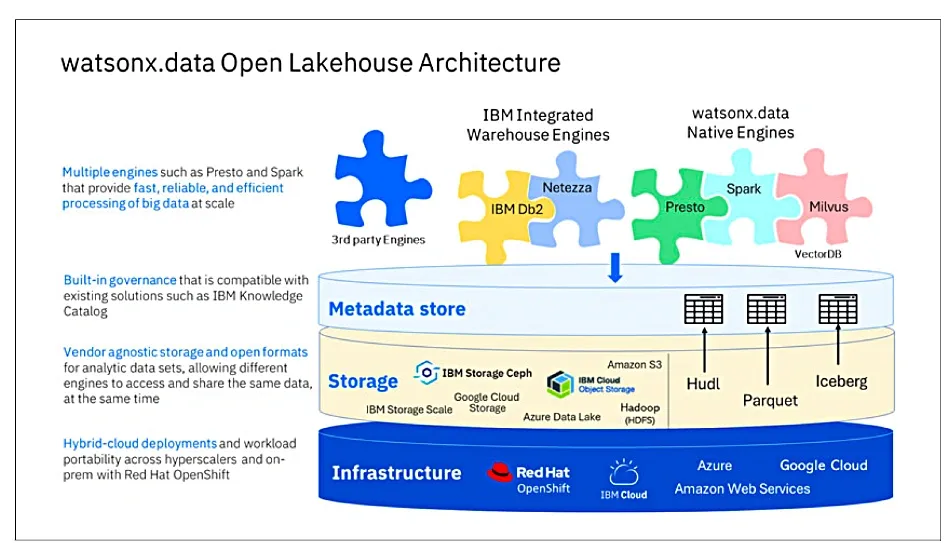
IBM’s watsonx.data functions as a data lakehouse, merging the extensive storage and processing power of a data lake with the high performance of a data warehouse.
Utilizing a scale-out architecture with commodity servers, it handles large volumes of both structured and unstructured data and supports the Apache Iceberg open table format for concurrent access by multiple processing engines.
IBM's watsonx.data and Storage Scale have combined their strengths to create an advanced AI processing and analytics platform.
This integrated solution merges the capabilities of a data lakehouse and a parallel file system, aiming to deliver high-performance AI with GPU Direct Storage (GDS) and Nvidia support for faster training of generative AI models.
Unified AI Data Platform
The watsonx.data component acts as a data lakehouse, merging the large-scale storage capabilities of a data lake with the performance of a data warehouse.
It supports the Apache Iceberg open table format for simultaneous data access by various processing engines.
Storage Scale, originally known as GPFS, serves as the underlying storage layer, providing a high-performance object storage service with its non-containerized High Performance S3 protocol.
This system supports various protocols, enabling a unified platform for analytics and AI.
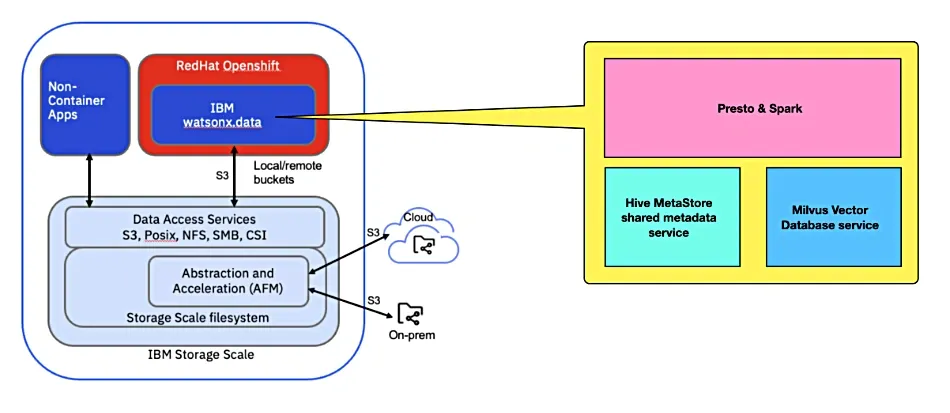
The architecture involves separate compute and storage layers. Compute tasks are handled by a Red Hat OpenShift container cluster running applications like Presto for SQL queries and Spark for big data processing.
The storage infrastructure consists of Storage Scale file system clusters, Active File Management (AFM) for data abstraction and acceleration, and S3 data access protocols for high-performance object storage.
AFM enables data sharing across clusters, creating a global namespace that includes NFS data sources. Remote S3 buckets are virtually integrated into the Storage Scale file system, allowing seamless data access without duplication.
The integration of NooBaa, an open-source object storage software acquired by Red Hat, enhances Storage Scale with features like caching, tiering, and encryption across hybrid cloud environments.
IBM's platform supports multiple storage tiers, optimizing both cost and performance, and provides a unified solution for AI training and inference. This approach aligns with IBM's strategy to offer comprehensive software solutions, positioning it alongside other major players in the AI data platform market.
The watsonx.data and Storage Scale bundle is detailed in an IBM Redbook, highlighting how this integration leverages enterprise storage features for advanced AI applications.















