
Large Language Models (LLMs) like GPT and BERT have transformed how we interact with technology—from powering chatbots to enabling real-time translations.
But how do these models actually come to life?
The development of an LLM involves a series of carefully orchestrated steps, which can be broadly grouped into four phases:
data preparation, model design, performance enhancement, and real-world deployment.
[Image Credits: VishnuNC
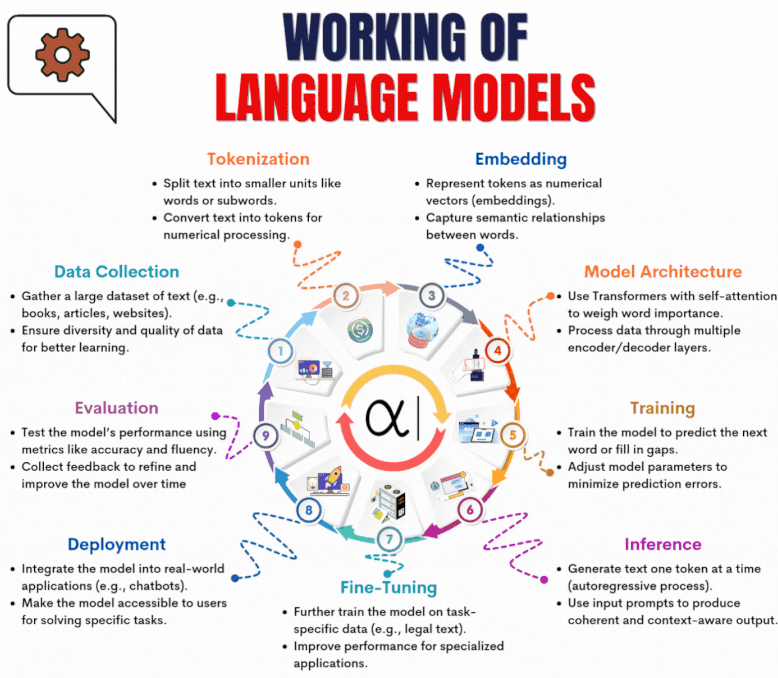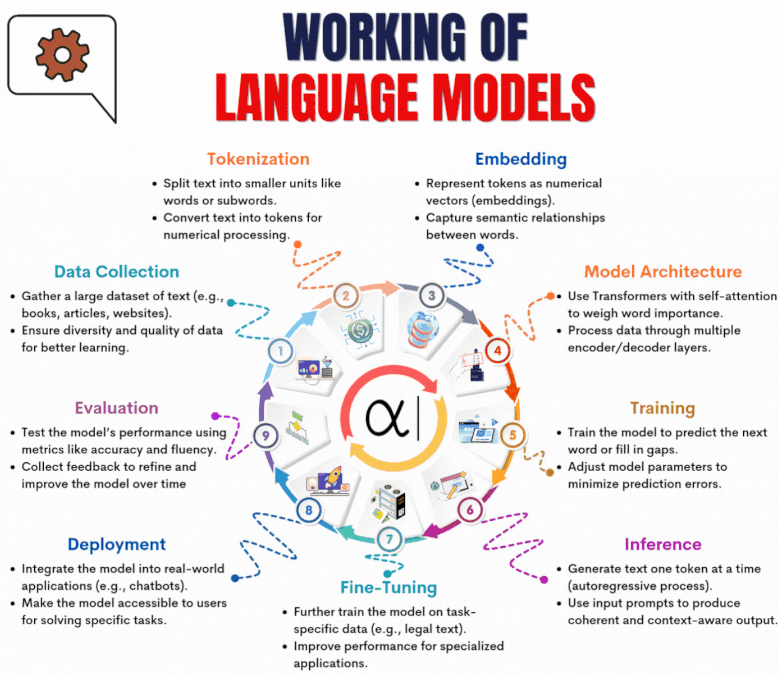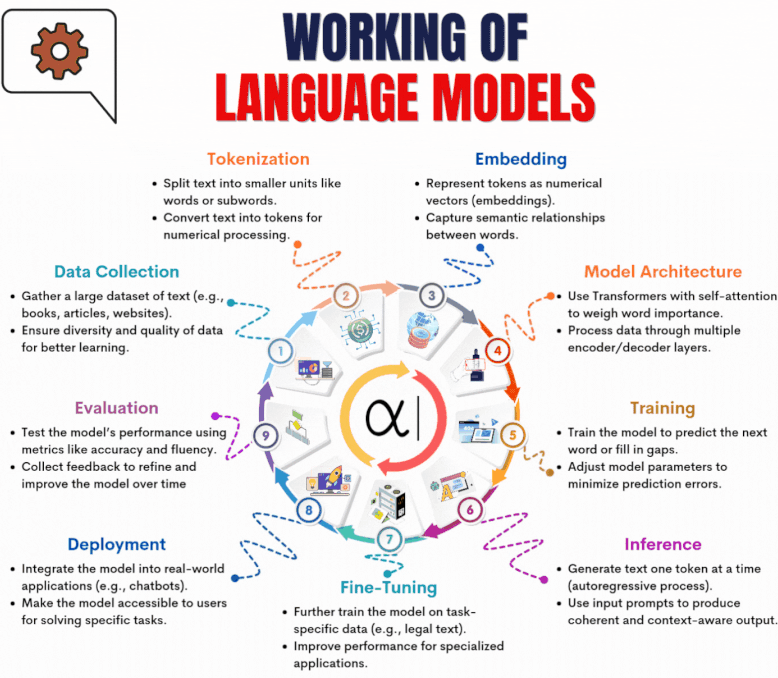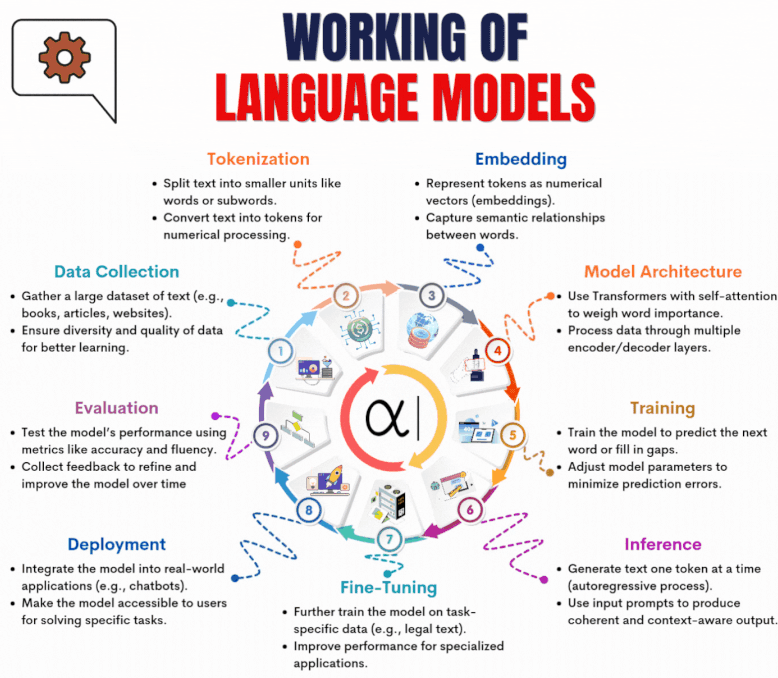
1. Data Preparation & Representation
Everything begins with data. A large and diverse collection of text—sourced from books, websites, research papers, and more—is gathered to teach the model language patterns, logic, and meaning.
This raw text is then processed into smaller units called tokens (such as words or subwords).
Each token is converted into a numerical format, known as an embedding, that captures the token’s contextual meaning and relationship with other words.
These embeddings serve as the model’s foundation for understanding and generating language.
2. Model Architecture and Training
Once the data is prepared, it’s time to build the model itself.
-
Most modern LLMs use a Transformer architecture, which leverages self-attention mechanisms to evaluate how words in a sentence relate to one another.
-
The model is trained on vast datasets by predicting missing or next words in a sequence, adjusting internal parameters to minimize prediction errors.
This phase requires significant computational power and can take weeks or months, depending on the scale.
3. Fine-Tuning for Specific Applications
After the initial training, the model can be further refined for specific industries or tasks through a process called fine-tuning.
This involves re-training the model on smaller, specialized datasets such as legal documents, medical records, or customer service transcripts.
Fine-tuning enables the model to perform better in focused use cases, ensuring it understands domain-specific language and nuances.
4. Deployment and Continuous Evaluation
With training complete, the model is ready to be deployed into real-world applications—chatbots, virtual assistants, content generators, and more.
-
When users input text, the model generates coherent responses in real time.
-
Post-deployment, it’s crucial to evaluate the model’s performance using metrics like accuracy, perplexity, and human feedback.
These insights help developers refine and update the model, making it more reliable and aligned with user needs over time.
From raw data to real-time interaction, the creation and use of LLMs is a blend of advanced engineering and iterative improvement.
As AI continues to evolve, these systems will only get smarter—and more embedded in our everyday lives.















